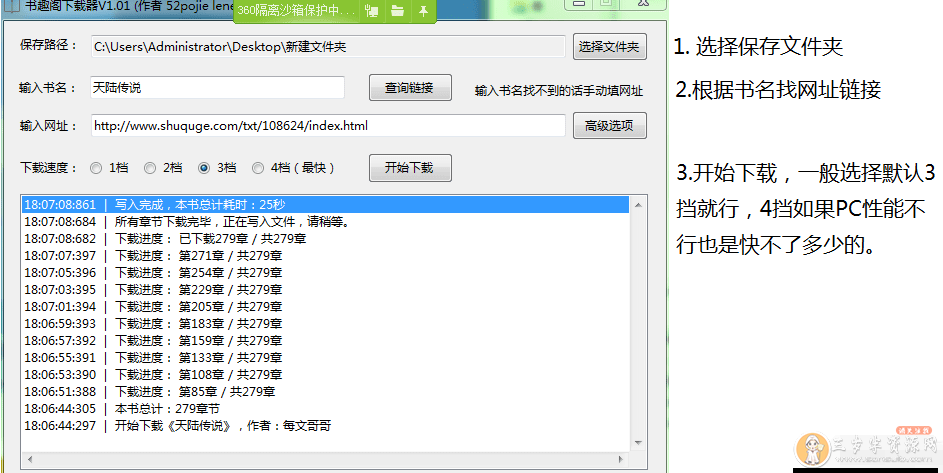
为了学习XPath做测试写了个爬小说的工具,这个网站大概有9万3千多本书,为了提高下载速度,用了任务工厂批量爬,最后一次性快速写入。发现这个网站自己的搜书功能都没法用,我直接把他所有书名都爬了保存在本地,这样可以直接根据书名找到URL。
涉及到广告的我基本都正则去掉了,段落默认换行,某行缩进4个字符,手机也能适应的,有其他需求的大家可以提出来,我后续再加,目前想到的就是后期支持多本开工。